自作 SQL 集
自作の SQL や便利な構文をまとめているページ。SQL Server 向け。
標準 SQL 集 と同じく kenkenpa198/mssql-with-docker からの引っ越しページ。
リンク
目次
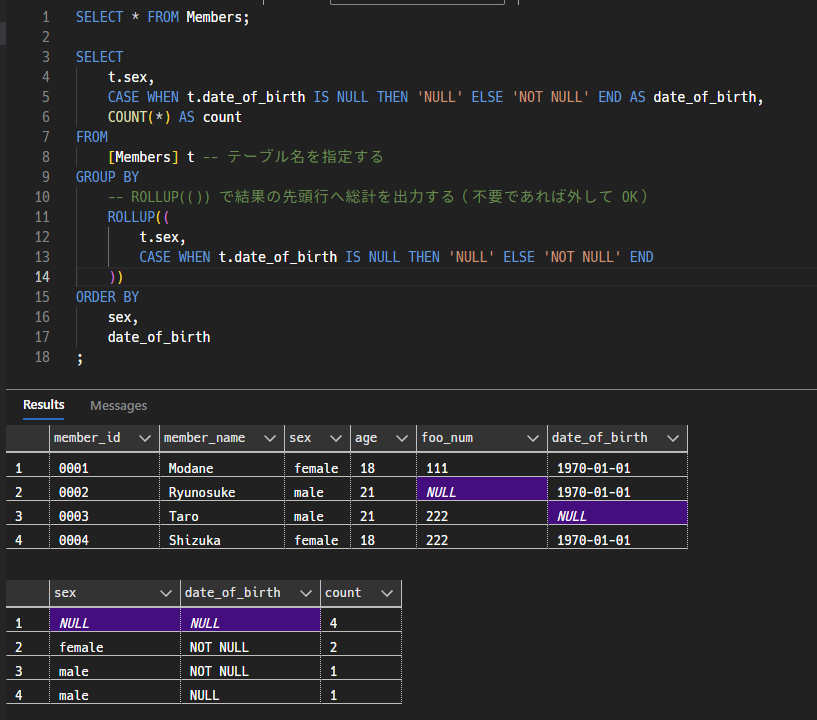
1. 値の組み合わせ毎の件数を取得する
指定したカラムのフィールドに存在する値の組み合わせ毎の件数を取得する。
めちゃくちゃ使っている。
SELECT
t.column_A,
t.column_B,
CASE WHEN t.column_C IS NULL THEN 'NULL' ELSE 'NOT NULL' END AS column_C,
COUNT(*) AS cnt
FROM
[tb] AS t -- テーブル名を指定する
GROUP BY
-- ROLLUP(()) で結果の先頭行へ総計を出力する(不要であれば外して OK)
ROLLUP((
t.column_A,
t.column_B,
CASE WHEN t.column_C IS NULL THEN 'NULL' ELSE 'NOT NULL' END
))
ORDER BY
column_A,
column_B,
column_C
;
実行結果イメージ:
参考文献:
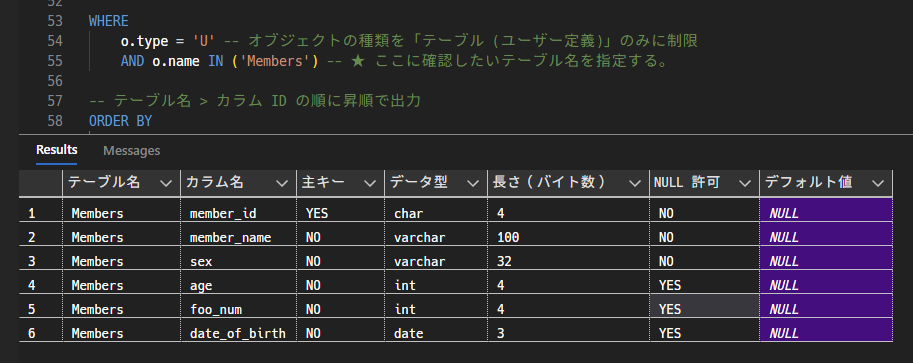
2. カラムの情報を見やすい形式で表示する
指定したテーブルの以下の情報を出力する。
- テーブル名
- カラム名
- 主キーか否か
- データ型
- 長さ
- NULL 許可か否か
- デフォルト値
★のコメント部分へテーブル名を指定する。配列形式での複数指定が可能。
PostgreSQL の \d tb のイメージ。
SQL Server だと手軽に確認する方法が限られるようなので作成した。
SELECT
o.name AS 'テーブル名',
c.name AS 'カラム名',
CASE
WHEN pk.is_primary_key = 1 THEN 'YES'
ELSE 'NO'
END AS '主キー',
type_name(c.user_type_id) AS 'データ型',
c.max_length AS '長さ(バイト数)',
CASE
WHEN c.is_nullable = 1 THEN 'YES'
ELSE 'NO'
END AS 'NULL 許可',
CASE
-- デフォルト値に含まれている '((' と '))' を除去する
WHEN LEFT(d.definition, 2) = '((' AND RIGHT(d.definition, 2) = '))' THEN SUBSTRING(d.definition, 3, LEN(d.definition) - 4)
-- デフォルト値に含まれている '(' と ')' を除去する
WHEN LEFT(d.definition, 1) = '(' AND RIGHT(d.definition, 1) = ')' THEN SUBSTRING(d.definition, 2, LEN(d.definition) - 2)
ELSE NULL
END AS 'デフォルト値'
-- ベースとなる sys.objects カタログビューテーブル。このビューへ各情報を結合する
FROM
sys.objects AS o
-- カラムのカタログビュー(カラム名やデータ型などの情報を保有)と内部結合
INNER JOIN sys.columns AS c
ON o.object_id = c.object_id
--インデックス関連のカタログビュー(PK の情報を保有)と外部結合
LEFT OUTER JOIN (
SELECT
ic.object_id,
ic.column_id,
i.is_primary_key
FROM
sys.indexes AS i
INNER JOIN sys.index_columns AS ic
ON
i.object_id = ic.object_id
AND i.index_id = ic.index_id
) pk
ON
o.object_id = pk.object_id
AND c.column_id = pk.column_id
-- デフォルト制約のカタログビュー(デフォルト値の情報を保有)と外部結合
LEFT OUTER JOIN sys.default_constraints AS d
ON
o.object_id = d.parent_object_id
AND c.column_id = d.parent_column_id
WHERE
o.type = 'U' -- オブジェクトの種類を「テーブル (ユーザー定義)」のみに制限
AND o.name IN ('Members') -- ★ ここに確認したいテーブル名を指定する。
-- テーブル名 > カラム ID の順に昇順で出力
ORDER BY
o.name,
c.column_id
;
実行結果イメージ:
参考文献:
- 【SQL】テーブルからカラム情報を取得する”sys.columns”の上手な使い方を伝授! | ポテパンスタイル
- SQL Server - 主キーの一覧を取得するクエリ - いちろぐ
- SQL Server のカタログビューからテーブルの定義書情報を取得する | JOHOBASE
- オブジェクト カタログ ビュー (Transact-SQL) - SQL Server | Microsoft Docs
3. グループ中で最大値を持つレコードを取得する
NOT 演算子及び EXISTS 述語を活用した大変便利な構文。
比較対象のグループ中で、最大値を持つフィールドが存在するレコードを取得する。
最大値と同じ行に存在する別カラムの値を 行の情報を崩さずに そのまま取得・利用できるのがポイント。
下記は「『member_id(会員 ID)毎の最新 order_at(受注日時)』と同じ行に存在する product_code(商品コード)を取得する」場合の例。
SELECT
hist.member_id,
hist.order_at,
hist.product_code
FROM
OrderHistories AS hist
WHERE
-- ここから……
NOT EXISTS (
SELECT
1
FROM
OrderHistories AS hist_sub -- 親の FROM 句に書いているテーブルと同じテーブルを指定
WHERE
hist.member_id = hist_sub.member_id -- グループの指定
AND hist.order_at < hist_sub.order_at -- 比較対象の列を指定
)
-- ここまで!
;
類似する書き方として以下が挙げられるが、上記のクエリはそれぞれの懸念点をまるまる解決できる。
GROUP BYで集約後、MAX()などの集約関数で取得する方法。- 一番最初に思いつくのがコレ。
- しかしこの方法だと、最大値を持つフィールドと同じ行にある別カラムの値を直接利用することができない(
GROUP BYした時点で「同じ行」である保証がなくなってしまう)。
- Window 関数
ROW_NUMBER()でランク付け後、ランクの値が1のものを取得する方法。- Window 関数を使うとこの書き方ができる。
- このやり方でも取得には問題ないが、参考サイトによると
NOT EXISTSの方が高速らしい。 NOT EXISTSの方はスニペット的にも使いまわしやすい。
その他補足内容は以下のとおり。
- 「最大の
order_at」が複数行存在した場合、複数行分SELECTされる。- 複数行
SELECTされた場合でも行ごとの情報は行ごとに保持される。 - このため、後続処理で重複排除が必要になる場合がある。主キー項目やレコードの単位に注意。
- 複数行
AND hist.order_at < ph_sub.order_atの比較演算子<を>にすると、最小値を持つ行を取ることができる。- パッと見だと書いてある内容がわかりづらいのが難点。
- とはいえ分解して読んでいくと「なるほどー」となる(その内解説記事を書いてみたいな?)。
参考文献:
- 同一グループの中で最大のレコードを取得する SQL を書く | Webシステム開発/教育ソリューションのタイムインターメディア
- 【SQL】グループごとに最大の値を持つレコードを取得する方法3選 | Takakisan
4. CSV などのデータファイルからインポート
SQL Server の BULK INSERT を使用した SQL 文。
CSV として作成したテストデータを対象のテーブルへまるごと取り込ませたいときに使う。
BULK INSERT members
FROM '/mount_dir/csv/members.csv'
WITH
(
FORMAT = 'CSV', -- CSV 形式で取り込み
FIRSTROW = 2 -- 読み込み開始行を指定
);
-- 細かく指定する場合は下記のような感じで
BULK INSERT members
FROM '/mount_dir/csv/members.csv'
WITH
(
DATAFILETYPE = 'char', -- 文字形式で取り込み
FIELDTERMINATOR = ',', -- 区切り文字を指定
ROWTERMINATOR = '\n', -- 行末を示す文字を指定
FIRSTROW = 2 -- 読み込み開始行を指定
);
参考文献: